PHYMES: Parallel HYpergraph MEssaging Streams
Introduction
🤔 What is PHYMES?
PHYMES (Parallel HYpergraph MEssaging Streams) is a subject-based message passing algorithm based on directed hypergraphs which provide the expressivity needed to model the heterogeneity and complexity of the real world. More details in the guide.
🤔 What can PHYMES do?
PHYMES can be used to build scalable Agentic AI workflows, (hyper)-graph algorithms, and world simulators. Examples for building a chat bot, a tool calling agent, and document RAG agent are provided using embedded token/tensor services or local/remote token/tensor services using OpenAI compatible APIs.
🤔 Why PHYMES?
🔐 written 100% in Rust for performance, safety, and security.
🌎 deployable on any platform (Linux, MacOs, Win, Android, and iOS) and in the browser (WebAssembly).
💪 scalable to massive data sets using columnar in memory format, parallel and stream native processing, and GPU acceleration.
🧩 interoperable with existing stacks by interfacing with cross-platform Arrow and WASM/WASI.
🔎 instrumented with tracing and customizable metrics to debug (hyper-)graph workflows faster.
🤔 Who and what inspired PHYMES?
PHYMES takes inspiration from real world networks including biological networks. The implementation of PHYMES takes inspiration from DataFusion, Pregel, and PyG.
🙏 PHYMES would not be possible if it were not for the amazing open-sources projects that it is built on top of including Arrow and Candle with full-stack support from Tokio, Dioxus, and [Wasmtime].
Repository
The phymes-core, phymes-ml, phymes-data, phymes-agents, phymes-server, phymes-app crates form a full-stack application that can run Agentic AI workflows, (Hyper-)Graph algorithms, and/or Simulate complex real world networks at scale using a web, desktop, or mobile interface.
| Crate | Description | Latest API Docs | README |
|---|---|---|---|
phymes-core | Core hypergraph messaging functionality | docs.rs | README |
phymes-ml | Support for machine learning (ML) and generative artificial intelligence (AI) | docs.rs | README |
phymes-data | Support for GPU accelerated data wrangling | docs.rs | README |
phymes-agents | Templates for building Agentic AI hypergraph messaging applications | docs.rs | README |
phymes-server | Server that runs the Agentic AI hypergraph messaging services | docs.rs | README |
phymes-app | Frontend UI for dynamically interacting with the Agentic AI hypergraph messaging services | docs.rs | README |
This book will introduce the core concepts behind phymes, tutorials for using the underlying libraries, and tutorials for building and running the full-stack application.
Getting started
This user guide will cover how to install the full-stack phymes application, develop with phymes, and deploy applications with phymes.
Installation of Phymes
Installation
Precompiled bundles for different Arch, OS, CUDA versions, and Token and Tensor services (e.g. for Agentic AI workflows) are provided on the releases page.
| Arch | OS | CUDA | Token service |
|---|---|---|---|
| x86_64-unknown-linux-gnu | ubuntu22.04, ubuntu24.04 | 12.6.2, 12.9.1 | candle, openai_api |
| wasm32-wasip2 | n/a | n/a | candle |
| wasm32-unknown-unknown | n/a | n/a | candle |
Token services for agentic AI workflows can embedded in the application using candle or accessed locally e.g., self-hosted NVIDIA NIMs docker containers or remotely e.g., OpenAI, NVIDIA NIMs, etc. that adhere to the OpenAI API schema using openai_api. Tensor services are embedded in the application using candle with CPU vectorization and GPU acceleration support.
To install the phymes application, download the precompiled bundle that matches your system and needs, and unzip the bundle. Double click on phymes-server to start the server. Navigate to http://127.0.0.1:4000/ to view the web application.
Alternatively, you can make REST API requests against the server using e.g., curl.
# Sign-in and get our JWT token
curl -X POST -u EMAIL:PASSWORD http://localhost:4000/app/v1/sign_in
# mock response {"email":"EMAIL","jwt":"JWTTOKEN","session_plans":["Chat","DocChat","ToolChat"]}
# Chat request
# Be sure to replace EMAIL and JWTTOKEN with your actual email and JWT token!
# Note that the session_name = email + session_plan
curl -H "Content-Type: application/json" -H "Authorization: Bearer JWTTOKEN" -d '{"content": "Write a python function to count prime numbers", "session_name": "EMAILChat", "subject_name": "messages"}' http://localhost:4000/app/v1/chat
Before running the phymes-server, setup the environmental variables as needed to access the local or remote OpenAI API token service endpoints.
# OpenAI API Key
export OPENAI_API_KEY=sk-proj-...
# NVIDIA API Key
export NGC_API_KEY=nvapi-...
# URL of the local/remote TGI OpenAI or NIMs deployment
export CHAT_API_URL=http://0.0.0.0:8000/v1
# URL of the local/remote TEI OpenAI or NIMs deployment
export EMBED_API_URL=http://0.0.0.0:8001/v1
WASM builds of phymes-server can be ran as stateless functions for embedded application using wasmtime or serverless applications.
# Sign-in and get our JWT token
wastime phymes-server.wasm -- --route app/v1/sign_in --basic-auth EMAIL:PASSWORD
# mock response {"email":"EMAIL","jwt":"JWTTOKEN","session_plans":["Chat","DocChat","ToolChat"]}
# Chat request
# Be sure to replace EMAIL and JWTTOKEN with your actual email and JWT token!
# Note that the session_name = email + session_plan
wastime phymes-server.wasm curl -- --route app/v1/chat --bearer-auth JWTTOKEN --data '{"content": "Write a python function to count prime numbers", "session_name": "EMAILChat", "subject_name": "messages"}'
The phymes application is available for desktop (Linux, Windows, MacOS) and mobile (Android, iOS), but requires building from source on the target platform (i.e., Linux for Linux desktop, Windows for Windows desktop, MacOS for MacOS desktop, Linux for Android, and MacOS for iOS). See [contributing] guide for detailed installation and build instructions.
Developing with Phymes
Setting up your build environment (Linux)
Setting up the Rust tool chain
Install the Rust tool chain:
https://www.rust-lang.org/tools/install
An example bash script for installing the Rust tool chain for Linux is the following:
apt update
DEBIAN_FRONTEND=noninteractive apt install --assume-yes git clang curl libssl-dev llvm libudev-dev make pkg-config protobuf-compiler
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
. "$HOME/.cargo/env"
rustup toolchain install stable --target x86_64-unknown-linux-gnu
rustup default stable
rustc --version
Also, make sure your Rust tool chain is up-to-date, because we always use the latest stable version of Rust to test this project.
rustup update stable
Setting up GPU acceleration with CUDA
Install CUDA for linux:
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
GPU acceleration with CUDA is currently only support for Linux (including WSL2) at this time. An example bash script for installing CUDA for WSL2 is the following:
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.6.2/local_installers/cuda-repo-wsl-ubuntu-12-6-local_12.6.2-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-6-local_12.6.2-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-6-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt update
sudo apt -y install cuda-toolkit-12-6
Please replace the repo and cuda versions accordingly. Check the Cuda installation
nvcc --version
nvidia-smi --query-gpu=compute_cap --format=csv
Install CuDNN backend for linux:
https://docs.nvidia.com/deeplearning/cudnn/installation/latest/linux.html
An example bash script for install CuDNN for Linux is the following:
wget https://developer.download.nvidia.com/compute/cudnn/9.5.1/local_installers/cudnn-local-repo-ubuntu2404-9.5.1_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2404-9.5.1_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2404-9.5.1/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt update
sudo apt -y install cudnn
Please replace the repo and cuda versions accordingly.
Setting up NVIDIA NIMs for local deployment
Obtain an NGC API key following the instructions.
Install the NVIDIA Container Toolkit following the instructions
Check that the installation was successful by running the following:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
The NGC catalogue can be viewed using NGC CLI. Install NGC following the instructions
Alternatively, the NGC catalogue can be viewed online. For example, the open-source Llama3.2 model can be deployed locally following the instructions, and alternatively accessed via the NVIDIA NIMs API if available (see the NIMs LLM [API](NIMs LLM API https://docs.nvidia.com/nim/large-language-models/latest/api-reference.html) for OpenAPI schema).
Setting up WASM build environment
Add the following wasm32 compilation targets from the nightly Rust toolchain:
rustup update nightly
rustup target add wasm32-unknown-unknown --toolchain nightly
rustup target add wasm32-wasip2 --toolchain nightly
In addition, we recommend using wasmtime for running wasi components
curl https://wasmtime.dev/install.sh -sSf | bash
Setting up Dioxus
The front-end application is built using dioxus to enable creating web, desktop, and mobile applications using Rust
# Build from source (can sometimes fail)
cargo install dioxus-cli
# Install using binstall (usually does not fail)
curl -L --proto '=https' --tlsv1.2 -sSf https://raw.githubusercontent.com/cargo-bins/cargo-binstall/main/install-from-binstall-release.sh | bash
cargo update
cargo binstall dioxus-cli
Setting up Android Studio
Installation of Android Studio is required to run virtual android phone emulations of the applicaiton or to test on a physical android device. Follow the below steps to install Android Studio on Linux.
First, install Linux 64 bit dependencies required to build Android applications
# add 32 bit architecture target
sudo dpkg --add-architecture i386
# add non-standard package repos for libncurses5
sudo tee -a /etc/apt/sources.list <<EOF
deb http://archive.ubuntu.com/ubuntu/ focal main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu/ focal-security main restricted universe multiverse
EOF
# install the dependencies
sudo apt-get update
sudo apt-get install libc6:i386 libncurses5:i386 libstdc++6:i386 lib32z1 libbz2-1.0:i386
sudo apt install default-jre
sudo apt install default-jdk
Second, install Android Studio. The simplest option is to download and untar in a directory of your choice. Then, move the files and folders to an accessible directory.
# cd to the directory for android-studio
mv android-studio /opt/android-studio/
sudo /opt/android-studio/bin/studio.sh
Third, use Android Studio to emulate a virtual android device by following the walkthrough under the section "Running the Emulator". Note that during the walkthrough, various packages are installed which require the configuration of permissions and environmental variables to work nicely with Dioxus.
# Set the environmental variable
export JAVA_HOME="/usr/lib/jvm/java-21-openjdk-amd64"
export ANDROID_HOME="$HOME/Android/Sdk"
export NDK_HOME="$ANDROID_HOME/ndk/29.0.13599879"
export PATH="$PATH:$ANDROID_HOME/emulator:$ANDROID_HOME/platform-tools"
# Fix the permission so that Dioxus can run Gradle
sudo chmod -R 757 ~/Android/Sdk
Finally, you should be able to build the phymes-app for android. Note that the emulator must be running before starting the phymes-app server.
dx serve -p phymes-app --platform android
Setting up your build environment (Android)
It is possible to build and run PHYMES directly on Android using Termux. Be sure enable developer options on Android and ensure to enable Disable child process restrictions.
Setting up Termux and Ubuntu
First, follow the instructions to install Termux on Android. Open Termux and install proot-distro by following the instructions on the repo.
Second, install Ubuntu using proot-distro:
# Install ubuntu (proot-distro reset ubuntu if something goes wrong)
proot-distro install ubuntu
proot-distro login ubuntu
# Setup a new user account
apt update && apt install sudo nano -y
adduser {USER} # enter password and optional information
nano /etc/sudoers # locate "root" and add entry for "{USER}"
su {USER} # switch to new user
# Setup for remote viewing
sudo apt upgrade && sudo apt update && sudo apt install udisks2
sudo rm /var/lib/dpkg/info/udisks2.postinst
echo "" >> /var/lib/dpkg/info/udisks2.postinst
sudo apt-mark hold udisks2
sudo apt install xfce4 xfce4-goodies
# If errors occur with the obove command run `sudo apt install gvfs-common gvfs-libs gvfs-daemons`
# Optional apps that can be useful Ubuntu
sudo apt install firefox gedit vlc dbus-x11 -y
Third, setup VNC server
sudo apt install tigervnc-standalone-server
echo "vncserver -geometry 1600x900 -xstartup /usr/bin/startxfce4 :1" >> /bin/vncstart
echo "vncserver -kill :1" >> /bin/vncstop
chmod +x /bin/vncstart
chmod +x /bin/vncstop
After starting vncserver, switch to a your VNC viewer of choice on android and connect using the password provided on the command line. We recommend bVNC.
Fourth, install visual studio code
# Install VS code
sudo apt-get install wget gpg -y
wget -qO- https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > packages.microsoft.gpg
sudo install -D -o root -g root -m 644 packages.microsoft.gpg /etc/apt/keyrings/packages.microsoft.gpg
sudo sh -c 'echo "deb [arch=amd64,arm64,armhf signed-by=/etc/apt/keyrings/packages.microsoft.gpg] https://packages.microsoft.com/repos/code stable main" > /etc/apt/sources.list.d/vscode.list'
rm -f packages.microsoft.gpg
sudo apt install apt-transport-https
sudo apt update
sudo apt install code
# Run VS code
code --no-sandbox
Optionally, add a shortcut for starting Ubuntu under your user account.
# If you are already in Termux
exit
logout
echo "proot-distro login --user {USER} ubuntu" >> $PREFIX/bin/ubuntu
chmod +x $PREFIX/bin/ubuntu
# Now you can start ubuntu with your user account using
ubuntu
Setting up your build environment (Windows, MacOS)
PHYMES can be also be built on Windows and MacOS. However, we have omitted the steps for now. Contributions to add the detailed steps are welcome 😊.
How to compile and run PHYMES
How to compile
This is a standard cargo project with workspaces. To build the different workspaces, you need to have rust and cargo and you will need to specify workspaces using the using the -p, --project flag:
cargo build -p phymes-core
CPU, GPU, and WASM-specific compilation features are gated behind feature flags wsl, gpu, and wasip2 respectively. The use of embedded Candle or OpenAI API token services are gated behind the feature flag candle and openai_api, which enables the use of Candle or OpenAI API token services. Enabling candle will force the application to use embedded Candle models even if openai_api is enabled. The use of HuggingFace models from the HuggingFace Hub API are gated behind the feature flag hf_hub.
The following will build the phymes-agents workspace with different configurations of CPU and GPU acceleration for Tensor and Token services:
# Native CPU for tensor operations and local/remote OpenAI API token services
cargo build -p phymes-agents --features wsl,openai_api --release
# Native CPU for tensor operations and embedded Candle for token services
cargo build -p phymes-agents --features wsl,candle --release
# Native CPU for tensor operations and embedded Candle with models from HuggingFace for token services
cargo build -p phymes-agents --features wsl,candle,hf_hub --release
# GPU support for tensor operations and local/remote OpenAI API token services
cargo build -p phymes-agents --features wsl,gpu,openai_api --release
# GPU support for tensor operations and embedded Candle for token services
cargo build -p phymes-agents --features wsl,gpu,candle --release
# GPU support for tensor operations and embedded Candle with models from HuggingFace for token services
cargo build -p phymes-agents --features wsl,gpu,candle,hf_hub --release
Please ensure that all CUDA related environmental variables are setup correctly for GPU acceleration. Most errors related to missing CUDA or CuDNN libraries are related to missing environmental variables particularly on WSL2.
export PATH=$PATH:/usr/local/cuda/bin:/usr/lib/x86_64-linux-gnu/
export LD_LIBRARY_PATH=/usr/lib/wsl/lib:/usr/local/cuda/lib64:/usr/local/cuda/lib64/stubs
The following will build the phymes-agents workspace as a WASIp2 component:
cargo build -p phymes-agents --target wasm32-wasip2 --no-default-features --features wasip2,candle --release
Mixing and matching features that are compilation target specific and compilation targets will result in build errors.
You can also use rust's official docker image:
docker run --rm -v ${pwd}:/phymes -it rust /bin/bash -c "cd /phymes && rustup component add rustfmt && cargo build -p phymes-core"
From here on, this is a pure Rust project and cargo can be used to run tests, benchmarks, docs and examples as usual.
Setting up the cache for running tests and examples
Many of the tests (and examples if running without the GPU or on WASM) depend upon a local cache of model assets to run. The following bash script can be used to prepare the local assets:
# ensure your home environmental variable is set
echo $HOME
# make the cache directory
mkdir -p $HOME/.cache/hf
# copy over the cache files from the root of the GitHub repository
cp -a .cache/hf/. $HOME/.cache/hf/
# download the model assets manually from HuggingFace
curl -L -o $HOME/.cache/hf/models--sentence-transformers--all-MiniLM-L6-v2/model.safetensors https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/model.safetensors?download=true -sSf
curl -L -o $HOME/.cache/hf/models--sentence-transformers--all-MiniLM-L6-v2/pytorch_model.bin https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/pytorch_model.bin?download=true -sSf
curl -L -o ~/.cache/hf/models--sentence-transformers--all-MiniLM-L6-v2/all-minilm-l6-v2-q8_0.gguf https://huggingface.co/sudomoniker/all-MiniLM-L6-v2-Q8_0-GGUF/resolve/main/all-minilm-l6-v2-q8_0.gguf?download=true -sSfv
curl -L -o $HOME/.cache/hf/models--Qwen--Qwen2-0.5B-Instruct/qwen2.5-0.5b-instruct-q4_k_m.gguf https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GGUF/resolve/main/qwen2.5-0.5b-instruct-q4_k_m.gguf?download=true -sSf
curl -L -o $HOME/.cache/hf/models--HuggingFaceTB--SmolLM2-135M-Instruct/smollm2-135m-instruct-q4_k_m.gguf https://huggingface.co/Segilmez06/SmolLM2-135M-Instruct-Q4_K_M-GGUF/resolve/main/smollm2-135m-instruct-q4_k_m.gguf?download=true -sSf
curl -L -o $HOME/.cache/hf/models--Alibaba-NLP--gte-Qwen2-1.5B-instruct/gte-Qwen2-1.5B-instruct-Q4_K_M.gguf https://huggingface.co/tensorblock/gte-Qwen2-1.5B-instruct-GGUF/resolve/main/gte-Qwen2-1.5B-instruct-Q4_K_M.gguf?download=true -sSf
Setting up local OpenAI API endpoints
Instead of using token credits with remote OpenAI API endpoints, it is possible to run the tests and examples locally using self-hosted open-source NVIDIA NIMs. Modify the following code depending upon the model(s) to be locally deployed:
# Text Generation Inference with Llama 3.2 (terminal 1)
export NGC_API_KEY=nvapi-
export LOCAL_NIM_CACHE=$HOME/.cache/nim
docker run -it --rm --gpus all --shm-size=16GB -e NGC_API_KEY -v "$LOCAL_NIM_CACHE:/opt/nim/.cache" -u $(id -u) -p 8000:8000 nvcr.io/nim/meta/llama-3.2-1b-instruct:1.8.6
# Text Embedding Inference with Llama 3.2 (terminal 2)
export NGC_API_KEY=nvapi-
export LOCAL_NIM_CACHE=$HOME/.cache/nim
docker run -it --rm --gpus all --shm-size=16GB -e NGC_API_KEY -v "$LOCAL_NIM_CACHE:/opt/nim/.cache" -u $(id -u) -p 8001:8000 nvcr.io/nim/nvidia/llama-3.2-nv-embedqa-1b-v2:latest
Note that the tests and examples assume that the local OpenAI API endpoints for NVIDIA NIMs are http://0.0.0.0:8000/v1 for Text Generation Inference (TGI, Chat) and http://0.0.0.0:8001/v1 for Text Embedding Inference (TEI, Embed), respectively. The defaults can be overwritten by setting the environmental variables for the TEI and TGI endpoints, respectively.
# URL of the local TGI NIMs deployment
export CHAT_API_URL=http://0.0.0.0:8000/v1
# URL of the local TEI NIMs deployment
export EMBED_API_URL=http://0.0.0.0:8001/v1
Also, be sure to add your NGC_API_KEY to the environmental variables before running tests or examples in a different terminal.
# NVIDIA API Key
export NGC_API_KEY=nvapi-...
Running the tests
Run tests using the Rust standard cargo test command:
# run all unit and integration tests with default features
cargo test
# run tests for the phymes-core crate with all features enabled
cargo test -p phymes-core --all-features
# run a specific test for the phymes-core crate with the wsl feature enabled
# and printing to the console
cargo test test_session_update_state -p phymes-core --features wsl -- --no-capture
# run the doc tests
cargo test --doc
You can find up-to-date information on the current CI tests in .github/workflows. The phymes-server, phymes-core, and phymes-agents crates have unit tests. Please note that many of the tests in the phymes-ml and phymes-agent crates do not run on the CPU due to the amount of time that it takes to run them. To run all tests in the phymes-ml and phymes-agents crates, either enable GPU acceleration with Candle using --features wsl,gpu,candle feature flag, or with OpenAI API local/remote token services using --feature wsl,openai_api or --feature wsl,gpu,openai_api feature flags depending upon GPU availability.
# run tests for the phymes-core crate
cargo test --package phymes-core --features wsl --release
# run tests for the phymes-data crate with GPU acceleration
cargo test --package phymes-data --features wsl,gpu --release
# or run tests for the phymes-data crate on the CPU
cargo test --package phymes-data --features wsl --release
# run tests for the phymes-ml crate with GPU acceleration with Candle assets
cargo test --package phymes-ml --features wsl,gpu,candle --release
# run tests for the phymes-ml crate with GPU acceleration with Candle assets from HuggingFace
cargo test --package phymes-ml --features wsl,gpu,candle,hf_hub --release
# or run tests for the phymes-ml crate on the CPU with OpenAI API token services
cargo test --package phymes-ml --features wsl,openai_api --release
# run tests for the phymes-agents crate with GPU acceleration with Candle assets
cargo test --package phymes-agents --features wsl,gpu,candle --release
# run tests for the phymes-agents crate with GPU acceleration with Candle assets from HuggingFace
cargo test --package phymes-agents --features wsl,gpu,candle,hf_hub --release
# or run tests for the phymes-agents crate on the CPU with OpenAI API token services
cargo test --package phymes-agents --no-default-features --features wsl,openai_api --release
# run tests for the phymes-server crate
cargo test --package phymes-server --features wsl --release
The tests can also be ran for WASM components. However, the WASM debug output is essentially useless, so it is recommend to debug the tests natively before testing on WASM
# build tests for the phymes-core crate
cargo test --package phymes-core --target wasm32-wasip2 --no-default-features --features wasip2 --no-run
# build tests for the phymes-core crate using wasmtime
# be sure to replace the -26200b790e92721b with your systems unique hash
wasmtime run target/wasm32-wasip2/debug/deps/phymes-core-26200b790e92721b.wasm
# run tests for the phymes-data crate
cargo test --package phymes-data --target wasm32-wasip2 --no-default-features --features wasip2,candle --no-run
# build tests for the phymes-data using wasmtime
# be sure to replace the -9ce9c7c7142d7db7 with your systems unique hash
wasmtime --dir=$HOME/.cache/hf --env=HOME=$HOME target/wasm32-wasip2/debug/deps/phymes_data-9ce9c7c7142d7db7.wasm
# run tests for the phymes-ml crate
cargo test --package phymes-ml --target wasm32-wasip2 --no-default-features --features wasip2,candle --no-run
# build tests for the phymes-ml crate using wasmtime
# be sure to replace the -9ce9c7c7142d7db7 with your systems unique hash
wasmtime --dir=$HOME/.cache/hf --env=HOME=$HOME target/wasm32-wasip2/debug/deps/phymes_ml-9ce9c7c7142d7db7.wasm
# run tests for the phymes-agents crate
cargo test --package phymes-agents --target wasm32-wasip2 --no-default-features --features wasip2,candle --no-run
# build tests for the phymes-agents crate using wasmtime
# be sure to replace the -9ce9c7c7142d7db7 with your systems unique hash
wasmtime --dir=$HOME/.cache/hf --env=HOME=$HOME target/wasm32-wasip2/debug/deps/phymes_agents-9ce9c7c7142d7db7.wasm
# run tests for the phymes-server crate
cargo test -p phymes-server --features wasip2-candle --no-default-features --target wasm32-wasip2 --no-run
# build tests for the phymes-server crate using wasmtime
# be sure to replace the -48a453bb50fd01da with your systems unique hash
wasmtime --dir=$HOME/.cache --env=HOME=$HOME target/wasm32-wasip2/debug/deps/phymes_server-48a453bb50fd01da.wasm
Running the examples
Run examples using the Rust standard cargo run command. A few simple examples are provided for the phymes-core and phymes-agents crates to provide new users a starting point for building application using the crates
# run examples for the phymes-core crate
cargo run --package phymes-core --features wsl --release --example addrows
# run examples for the phymes-ml and phymes-agents crates with GPU acceleration with Candle assets
cargo run --package phymes-ml --features wsl,gpu,candle --release --example chat -- --candle-asset SmoLM2-135M-chat
cargo run --package phymes-agents --features wsl,gpu,candle --release --example chat_agent_session
# or run examples for the phymes-ml and phymes-agents crates on the CPU with OpenAI API token services
cargo run --package phymes-ml --no-default-features --features wsl,openai_api --release --example chat -- --openai-asset Llama-3.2-1b-instruct
cargo run --package phymes-agents --no-default-features --features wsl,openai_api --release --example chat_agent_session
The examples can also be ran using WASM. However, all assets needed to run the example need to be provided locally unlike native where we can rely on the HuggingFace API to download and cache models for us. The following bash script can be used to build the examples in wasm and run the examples using wasmtime:
# build examples for the phymes-core crate
cargo build --package phymes-core --target wasm32-wasip2 --no-default-features --features wasip2 --release --example addrows
# run the examples for the phymes-core crate
wasmtime run target/wasm32-wasip2/release/examples/addrows.wasm
# build the chat example for the phymes-ml crate
cargo build --package phymes-ml --target wasm32-wasip2 --no-default-features --features wasip2,candle --release --example chat
# run the chat example for the phymes-agents crate
wasmtime --dir="$HOME/.cache/hf" --env=HOME=$HOME target/wasm32-wasip2/release/examples/chat.wasm --weights-config-file "$HOME/.cache/hf/models--HuggingFaceTB--SmolLM2-135M-Instruct/config.json" --weights-file "$HOME/.cache/hf/models--HuggingFaceTB--SmolLM2-135M-Instruct/smollm2-135m-instruct-q4_k_m.gguf" --tokenizer-file "$HOME/.cache/hf/models--HuggingFaceTB--SmolLM2-135M-Instruct/tokenizer.json" --tokenizer-config-file "$HOME/.cache/hf/models--HuggingFaceTB--SmolLM2-135M-Instruct/tokenizer_config.json" --candle-asset "SmoLM2-135M-chat"
# build the chat_agent_session example for the phymes-agents crate
cargo build --package phymes-agents --target wasm32-wasip2 --no-default-features --features wasip2,candle --release --example chat_agent_session
# run the chat_agent_session example for the phymes-agents crate
wasmtime --dir="$HOME/.cache/hf" --env=HOME=$HOME target/wasm32-wasip2/release/examples/chat_agent_session.wasm
Clippy lints
We use clippy for checking lints during development, and CI runs clippy checks.
Run the following to check for clippy lints:
cargo clippy --all-targets
If you use Visual Studio Code with the rust-analyzer plugin, you can enable clippy to run each time you save a file. See https://users.rust-lang.org/t/how-to-use-clippy-in-vs-code-with-rust-analyzer/41881.
One of the concerns with clippy is that it often produces a lot of false positives, or that some recommendations may hurt readability. We do not have a policy of which lints are ignored, but if you disagree with a clippy lint, you may disable the lint and briefly justify it.
Search for allow(clippy:: in the codebase to identify lints that are ignored/allowed. We currently prefer ignoring lints on the lowest unit possible.
- If you are introducing a line that returns a lint warning or error, you may disable the lint on that line.
- If you have several lints on a function or module, you may disable the lint on the function or module.
- If a lint is pervasive across multiple modules, you may disable it at the crate level.
Rustfmt Formatting
We use rustfmt for formatting during development, and CI runs rustfmt checks.
Run the following to check for rustfmt changes (before submitting a PR!):
cargo fmt --all -- --check
Rustdocs and mdBook for documentation
We use doc for API documentation hosted on crates.io and mdBook for the guide and tutorial static website with a mermaid preprocessor mdbook-mermaid is used for generating mermaid diagrams hosted on GitHub Pages.
Run the following to create the API documentation using doc:
cargo doc --document-private-items --no-deps -p phymes-core
cargo doc --document-private-items --no-deps -p phymes-ml
cargo doc --document-private-items --no-deps -p phymes-data
cargo doc --document-private-items --no-deps -p phymes-agents
cargo doc --document-private-items --no-deps -p phymes-server
cargo doc --document-private-items --no-deps -p phymes-app
Please visit the mdBook guide for installation and usage instructions. Also, please visit mdbook-mermaid for installation instructions. Run the following to create the the guide and tutorials using mdBook:
mdbook build phymes-book
Running Benchmarks
Running benchmarks are a good way to test the performance of a change. As benchmarks usually take a long time to run, we recommend running targeted tests instead of the full suite.
# run all benchmarks
cargo bench
# run phymes-agents benchmarks
cargo bench -p phymes-agents
# run benchmark for the candle_asset functions within the phymes-agents crate
cargo bench -p phymes-agents --bench candle_asset
To set the baseline for your benchmarks, use the --save-baseline flag:
git checkout main
cargo bench -p phymes-agents --bench candle_asset -- --save-baseline main
git checkout feature
cargo bench -p phymes-agents --bench candle_asset -- --baseline main
Running the CI locally
Continuous integration and deployment are orchestrated using GitHub actions on each pull request (PR) to the main branch. Unfortunately, debugging the CI/CD can be quite difficult and time consuming, so we recommend testing locally using a self-hosted runner.
First, follow the instructions for downloading, configuring, and using the self-hosted runner.
Second, be sure to change runs-on: ubuntu-latest to runs-on: self-hosted in the YAML for all workflow files for each job.
Third, Run the actions-runner. Now, when you open a PR, the CI will run locally on your machine.
Deploying Phymes
Deployment on Web, Desktop, and Mobile
The phymes-core, phymes-agents, phymes-server, phymes-app crates form a full-stack application that can run Agentic AI workflows, Graph algorithms, or Simulate networks at scale using a web, desktop, or mobile interface. Both the frontend and server need to be built in --release mode for improved performance and security.
Web
First, build the frontend application using dioxus
dx bundle -p phymes-app --platform web --release
Second, build the server with the desired features.
# GPU support and Candle token service
cargo build --package phymes-server --features wsl,gpu,candle --release
# Or OpenAI API
cargo build --package phymes-server --no-default-features --features wsl,openai_api --release
Third, move the server executable to the same directory as the web assets
mv target/release/phymes-server target/dx/phymes-app/release/web/public/
Fourth, run the application and navigate to http://127.0.0.1:4000/
cd target/dx/phymes-app/release/web/public
./phymes-server
Desktop
First, build the frontend application
cargo build -p phymes-app --features desktop --release
Second, build the phymes-server application with the desired features.
# GPU support and Candle token service
cargo build --package phymes-server --features wsl,gpu,candle --release
# Or OpenAI API
cargo build --package phymes-server --no-default-features --features wsl,openai_api --release
Third, launch the phymes-app executable
./target/release/phymes-app
Fourth, launch the phymes-server executable
./target/release/phymes-server
Mobile (Android)
First, build the frontend application
# for Android
dx build -p phymes-app --platform android --release
# for iOS
dx build -p phymes-app --platform ios --release
Second, build the phymes-server application with the desired features. Note that Dioxus
# GPU support and Candle token service
cargo build --package phymes-server --features wsl,gpu,candle --release
# Or OpenAI API
cargo build --package phymes-server --no-default-features --features wsl,openai_api --release
Third, launch the phymes-app executable on a device emulator or on the physical device.
Fourth, launch the phymes-server executable
./target/release/phymes-server
WASM
First, build the phymes-server application with Candle token services.
cargo build --package phymes-server --no-default-features --features wasip2,candle --target wasm32-wasip2 --release
Second, iteratively query the phymes-server using wasmtime.
# Sign-in and get our JWT token
wastime --dir=$HOME/.cache phymes-server.wasm --route app/v1/sign_in --basic_auth EMAIL:PASSWORD
# mock response {"email":"EMAIL","jwt":"JWTTOKEN","session_plans":["Chat","DocChat","ToolChat"]}
# Get information about the different subjects
wastime --dir=$HOME/.cache phymes-server.wasm curl --route app/v1/subjects_info --bearer_auth JWTTOKEN --data '{"session_name":"EMAILChat","subject_name":"","format":"Bytes","publish":"None","content":"","metadata":"","stream":false}'
# Chat request
# Be sure to replace EMAIL and JWTTOKEN with your actual email and JWT token!
# Note that the session_name = email + session_plan
wastime --dir=$HOME/.cache phymes-server.wasm curl --route app/v1/chat --bearer_auth JWTTOKEN --data '{"content":"Write a python function to count prime numbers","session_name":"EMAILChat","subject_name":"messages","format":"Bytes","publish":"None","metadata":"","stream":true}'
no_std
All PHYMES crates can be compiled for the wasm32-unknown-unknown target with no_std for integration with embedded and serverless applications
Deploying with local or remote OpenAI API compatible token service endpoints
OpenAI API compatible token service endpoints are supported for local (e.g., NVIDIA NIMs) or remote (e.g., OpenAI or NVIDIA NIMs). Please see the guide for local NVIDIA NIMs token service deployment.
Before running the phymes-server, setup the environmental variables as needed to access the local or remote token service endpoint as described in the guide, or specify the endpoint urls in the CandleEmbedConfig and CandleChatConfig, respectively.
Debugging the PHYMES deployment
We recommend debugging the application using two terminals: one for phymes-app and another for phymes-server. Dioxus provides a great development loop for front-end application development with nifty hot-reloading features, but requires it's own dedicated terminal to run. Tokio provides an industry grade server along with nifty security features. During development (specifically, debug mode), the server permissions are relaxed to enable iterative debugging of the application. The phymes-core, phymes-ml, phymes-data, phymes-agents, and phymes-server all use the Tracing crates for tracing and logging functionality. The packages and verbosity of console logging can be specified on the command line using the RUST_LOG environmental variable.
In the first terminal:
dx serve -p phymes-app --platform web
In the second terminal:
# default log level
cargo run -p phymes-server --features wsl,gpu,candle
# only INFO level logs
RUST_LOG=phymes_server=INFO cargo run -p phymes-server --features wsl,gpu,candle
# DEBUG and INFO level logs for phymes-server, phymes-core, and phymes-ml with BACKTRACE level 1
RUST_BACKTRACE=1 RUST_LOG=phymes_server=DEBUG,INFO,ERROR,phymes_data=DEBUG,INFO,ERROR,phymes_core=DEBUG,INFO,ERROR,phymes_ml=DEBUG,INFO,ERROR cargo run -p phymes-server --features wsl,gpu,candle,hf_hub
PHYMES Core
Synopsis
The PHYMES core crate implements the core algorithm for parallel and streaming hypergraph message passing. Similar to Pregel, messages are passed to computational nodes at each superstep. The messaging passing continues until a criteria is met or a maximum number of supersteps have been reached. Unlike Pregel, PHYMES does not operate over an undirected graph, but over a directed hypergraph using a publish-subscribe model where subjects are nodes and tasks are hyperedges and the directionality is determined by whether subjects are subscribed to or published on. In short, tasks subscribe to subjects, process subjects, and then publish their results to subjects.
Phymes algorithm
Hypergraphs are powerful representations for the complexities of the real world
Hypergraphs are a generalization of graphs that can better represent the complexities of the real world. For example, biochemical networks can be represented as a directed hypergraph where nodes are molecules and hyperedges are reactions that catalyze the conversion of molecules into other molecules. The directionalty of the reaction is lost when represented as an undirected graph and the grouping of molecules involved in the reaction is lost when using directed graphs.
Mathematically, the biochemical reaction hypergraph can be represented as an incidence matrix where the rows corresponding to molecules, the columns correspond to reactions, and the entries are positive or negative integers corresponding the the number of molecules consumed or produced by the reaction.
While simplistic, this representation is already useful for decision science whereby one can optimize the molecules flow through the network using (mixed integer)-(non)-linear programming, for simulation whereby one can reverse parameter fit the network to data and then forward simulate the network using numerical integration solvers, for exploratory data science whereby unsupervised methods such as PCA, KNN clustering, etc can be applied to learn about the network topological and dynamic properties, and for forecasting whereby once can fit a hypergraph neural network to make predictions about future node, hyperedge, or hypergraph properties.
Hypergraphs can be further decomposed into binary and unary hyper edges. This decomposition better aligns with the binary and unary operators of computational graphs. This decomposition also aligns well with biochemical computational graphs where reactions can be broken down into steps describing the binding of individual molecules to a catalyst, the rearrangement of atoms, and the unbinding of individual molecules. When the exact steps are not known, a set of possible hypergraph configurations can be constructed and then weighted by their probability or used as the basis for follow up experiments to determine the exact steps.
Phymes is a parallel hypergraph message streaming algorithm
Phymes is designed around the concept of a hypergraph where subjects are nodes and tasks are hyperedges. Phymes uses a publish-subscribe message passing scheme to implement the hypergraph. Specifically, tasks subscribe to and publish on subjects. The addition of processor metrics, tracing, and the subject tables themselves provides transparency on all hypergraph computation steps.
The execution of tasks is done in parallel and Asynchronously. Tasks can either always subscribe to a subject or conditionally subscribe when a subject is updated. Tasks run only when all of their subscriptions are ready. Conditional subscription on updated subjects enables the coding of first order logic to control when tasks execute. Tasks then publish the results of their computation to subjects. The execution of tasks is coordinated through supersteps where ready tasks are ran in parallel.
Phymes incorporates decomposition of hyperedges. Tasks are composed of processes that iteratively operate over streams of subject messages. The chaining of processors enables the representation of complex computational graphs. The streaming of messages enables the scaling to massive data sets that do not fit into memory on a single node. The computation over streaming messages enables parallel and Asynchronous execution of tasks at each superstep.
Phymes provides the algorithmic basis and computational framework for implementing efficient and scalable algorithms for decision science, simulation, data science, and machine learning. In particular, phymes provides a cross platform, secure, performant, and transparent Agentic AI framework with support for complex Data and data science function calls.
Phymes glossary
Session
Manifestation of particular task hypergraph that a user can publish subjects to and stream subscribed subjects from. The SessionContext maintains the metrics, tasks, state, and runtime (discussed below). The SessionStream manages the subscribing and publishing of subjects by tasks by iteratively running a "super step" via SessionStreamStep which invokes tasks for which all of their subscribed subjects have been updated and then updates the subjects with the published results of each ran task.
State
The application state are subjects (i.e., tables) that implement the ArrowTableTrait. Subjects include data tables, configurations (e.g., single row tables where the schema defines the parameters and the first row defines the values for the parameters), and aggregated metrics. Subjects can be subscribed to and published to from multiple tasks, which results in a hypergraph structure.
Metrics
Recorded per ArrowProcessorTrait and aggregated at the query level. Examples of baseline metrics include runtime and processed table row counts. Additional metrics can be defined by the user.
Tasks
The unit of operation. Tasks are hyperedges in the task hypergraph. Tasks are often referenced as Agents or Tools in the agentic AI world or as execution plan partitions in the database world. The trait ArrowTaskTrait defines the behavior of the task through the run method which is responsible for subscribing to subjects, processing them by calling a series of structs implementing the ArrowProcessorTrait, and then publishing outgoing messages to subjects. The struct that implements the ArrowTaskTrait includes a name for the task, metrics to track the task processes, runtime information, access to the complete or a subset of the complete state, and a ArrowProcessorTrait. The processing of messages is implemented by the ArrowProcessorTrait, which recieves the incoming message, metrics, state, and runtime from the ArrowTaskTrait.
Process
The processing of messages is implemented by the ArrowProcessorTrait, which recieves the incoming message, metrics, state, and runtime from the ArrowTaskTrait. The processor operates over streams of RecordBatchs which enables scaling across multiple nodes, and allows for calling native or remote (via RPC) components or provider services. Tasks can call a series of structs implementing ArrowProcessorTrait forming a complex computational chain over subscribed messagings. Processes are intended to be quasi-stateless, and therefore all state and runtime artifacts are passed as parameters to the process method. For example, the configurations for the processor method are passed as state tables, the runtime artifacts are set in the runtime, and the metrics for recording the time and number of rows processed and other user defined criteria are all passed as input paramters. The only state maintained by the processors are the subscribed subjects, subjects to publish, and subjects to pass through to the next process in the chain.
Messages
The unit of communication between tasks. ArrowIncomingMessagees are sent to tasks in uncompressed tables or compressed IPC format; while ArrowOutgoingMessagees are sent from tasks in a streaming format to enable lazy and parallel execution of the task processor computational chain. The streaming format is used as both input and output for processors to enable scaling to massive data sizes that can be efficiently distributed across multiple nodes.
Tables
The unit of data. Tables implement the ArrowTableTrait and facilitate the manipulation of Arrow RecordBatches. RecordBatches are a highly efficient columnar data storage format that facilitate computation on the CPU and transfer to the GPU for accelerated computation. Tables can be seralized when sending over the wire, and converted to and from various formats including JSON as needed.
Runtime Env
Defines how Processes are ran. For AI/ML tasks, the RuntimeEnv may include model weights loaded into GPU memory. For Data tasks, the RuntimeEnv may include CPU settings and memory or wall clock constraints. Similar to state, the RuntimeEnv artifacts are intended to be shared between different processes. For example, a single LLM model weights maybe used by multiple processors in parallel or re-used between queries to the same session without having to reload the weights into memory each time. The runtime environment can also be thought of as services that processes can share. For example, instead of hosting an LLM locally, the runtime can define an API to call to generate tokens remotely which provides flexibility and scalability depending upon the needs of the application.
Example: Single Source Shortest Paths (SSSP)
SSSP computes the shortest path distance from a source node to all reachable destination nodes. Loops are ignored.
In progress...
Example: Biochemical network simulator
A simple network describing the interconnection of molecules is simulated until a steady state is reached. The time axis is uniformly discretized and walked along until there is no further change in molecule amounts. If the change in any molecule amounts is greater than a given threshold, the step is repeated with a finer grained time delta. If the change in all molecules is below a given threshold, the time delta is increased on the next step.
In progress...
Example: Agentic AI
See phymes-agents crate for examples building a chat bot, tool calling agent, and document RAG workflow.
PHYMES Machine Learning (ML)
Synopsis
The PHYMES agent crate implements the functionality for Generative AI. Specifically, the crate implements functionality for native rust text generation inference and text embedding inference using the candle crates from HuggingFace. All functionality can be GPU accelerated using CUDA and CuDNN.
Model Assets
Synopsis
This tutorial describes how the Candle model assets are used to support text generation inference (TGI) and text embedding inference (TEI) services that are needed for agentic AI. A chat model that provides TGI via the command line is provided in the examples.
Tutorial
Candle assets
The candle assets that enable TGI and TEI include the model weights, configs, and tokenizer. Pytorch .bin, SafeTensor model.safetensor, and .gguf formats are supported. All assets can be downloaded using the HuggingFace API. phymes-agents provides a unified interface that hides away the nuances of different model architectures, quantizations, etc. to provide a more streamlined experience when working with different models similar to other agentic AI libraries.
Text generation inference (TGI)
The TGI model classes supported currently include Llama and Qwen and their quantized versions. Please reach out if other model classes are needed.
Text embedding inference (TEI)
The TEI model classes supported currently include BERT and QWEN and their quantized versions. Please reach out if other model classes are needed.
WASM compatibility
TGI, TEI, and Tensor operations are all supported in WASM with simd128 vectorization acceleration when supported by the CPU. Note that the SafeTensor format cannot be used with WASM. The maximum model weight memory cannot exceed 2 GB. The HuggingFace API can also not be used.
OpenAI API compatible assets
Complementary to the embedded AI functionality of Candle-based assets, support for local e.g., self-hosted NVIDIA NIMs docker containers or remote e.g., OpenAI, NVIDIA NIMs, etc. OpenAI API compatible assets are also provided. Please see the contributing guide for more details on using OpenAI API compatible endpoints.
WASM compatibility
API requests over the wire are not supported in WASM. Projects such as WASMCloud and WRPC would enable the use of OpenAI API requests in a hybrid native, cloud, and WASM context. PHYMES will look to support OpenAI API requests using WRPC in the future.
Example: Chat
Synopsis
This tutorial describes how the Chat Processor uses the phymes-ml and phymes-core crates to run a text generation inference using embedded Candle assets. The chat executable is provided in the examples.
Tutorial
In progress...
Next steps
The Chat Processor comes with a number of default configurations including the model, number of tokens to sample, temperature of sampling, etc. that can be modified by the user.
PHYMES Extract Transform Load (Data)
Synopsis
The PHYMES etl crate implements the functionality for data wrangling and exploratory data analysis that are often used as function or tool calls in Agentic AI workflows. Specifically, the crate implements functionality to convert documents into columnar tables as implemented in phymes-core, Data operators over columnar tables, and data visualization from columnar tables. Functionality for general tensor operations using the candle crates from HuggingFace, PDF parsing using the lopdf crate, and data visualization using the plotly crate. All tensor operations can be GPU accelerated using CUDA and CuDNN.
Data Operators
Synopsis
This tutorial describes how the Candle Tensor class can provide GPU accelerated Data operations such as sorting, joining, and group aggregation to build powerful tools and complete Data pipelines that can be integrated with agentic AI. A etl executable that provides Data operators over tabular data via the command line is provided in the examples.
Tutorial
Tensor operations
The Tensor class combined with Arrow's Compute library provides the primitives for select, sort, join, and aggregate operations with CPU and GPU accelerated that can be combined into complete Data pipelines over columnar tables. Custom operations such as document chunking required for document RAG can also be created. Operations are either Unary or Binary, and composed into complex execution graphs analogous to database query plans that operate over colunar tables. All available functions are wrapped into a unified interface that supports tool calling with agents.
The following primitive and non-primitive Rust types are supported for all data operations: u8, u32, i64, f32, f64, and String. Candle Tensor also supports bf16 and f16 types, but these are not yet fully supported by Apache Arrow at the time of writing. In addition, nested types (either fixed sized list or variable sized lists) in combination with the supported primitive and non-primitive Rust types are also supported e.g., Vec<Vec<f32>> or Vec<Vec<u32>> that are often used for embeddings.
WASM compatibility
Tensor operations are supported in WASM with simd128 vectorization acceleration when supported by the CPU.
Document Parsers
Synopsis
This tutorial describes how the lopdf crate provides PDF parsing functionality that can be combined with Data pipelines and Agentic AI. A pdf executable that provides PDF parsing is provided in the examples.
Tutorial
PDF parsers
Text is extracted from PDF documents and returned as columnar tables following the schema used for document processing in the phymes-agents session plans. Simple cleaning of the extracted text is provided by default, e.g., removing extra white spaces and joining lines and paragraphs. While the sequence of text is maintained, the hierarchy is lost and would require a proper OCR solution such as the NVIDIA NIMS nemoretriever-parse or PaddleOCR which would also provide image and table parsing and can be hosted as microservices and called via API in the future.
WASM compatibility
Text extraction from PDF documents is supported in WASM with simd128 vectorization acceleration when supported by the CPU.
Data visualization
Synopsis
This tutorial describes how the Plotly and Mermaid.js provide data visulaization functionality that can be combined with Data pipelines and Agentic AI. A etl executable that provides Data operators over tabular data via the command line is provided in the examples.
Tutorial
Data visualization with Plotly
In progress...
Data visualization with Mermaid.js
In progress...
WASM compatibility
Plotly and Mermaid.js are compatible with WASM.
Example: Data with PDF parsing and data visualization
Synopsis
This tutorial describes how the Ops Processor uses the phymes-data and phymes-core crates to orchestrate complex Data pipelines on datasets that may not fit in memory. The etl executable is provided in the examples.
Tutorial
In progress...
Next steps
The Ops Processor can be chained in a number of ways by the user to cover the functionality of e.g., Python Pandas or PostgreSQL with the benefit of GPU acceleration and control over how data streams are processed.
PHYMES AI Agents
Synopsis
The PHYMES agent crate implements the functionality to enable Agentic AI on desktop, mobile, and in the browser. Templates to create a chatbot, tool calling agent, and document RAG agent are provided and will be expanded in the future.
Session Plan: Chat Agent
Synopsis
This tutorial describes how the Chat Agent Session Plan uses the phymes-agent and phymes-core crates to build a simple chat agent. The chat agent is provided in the examples.
Tutorial
The simplest agentic AI architecture is that of a chat agent, which can be modeled as a static directed acyclic graph.
stateDiagram-v2
direction LR
[*] --> chat_agent: Query
chat_agent --> [*]: Response
The session starts with a query to the chat_agent from the user, and the chat_agent runs text generation inference to respond back to the user.
Under the hood, the states of the application are determined by the subjects that are subscribed to and published on by the user and the chat_agent.
sequenceDiagram
user->>messages: 1
messages->>chat_agent: 2
config->>chat_agent: 3
chat_agent->>messages: 4
messages->>user: 5
The sequence of actions are the following:
- The user publishes to messages subject
- The chat_agent subscribes to messages subject when there is a change to the messages subject table.
- The chat_agent subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chat_agent.
- The chat_agent performs text generation inference based on the messages subject content and publishes the results to the messages subject.
- The user subscribes to messages subject where there is a change to the messages subject table.
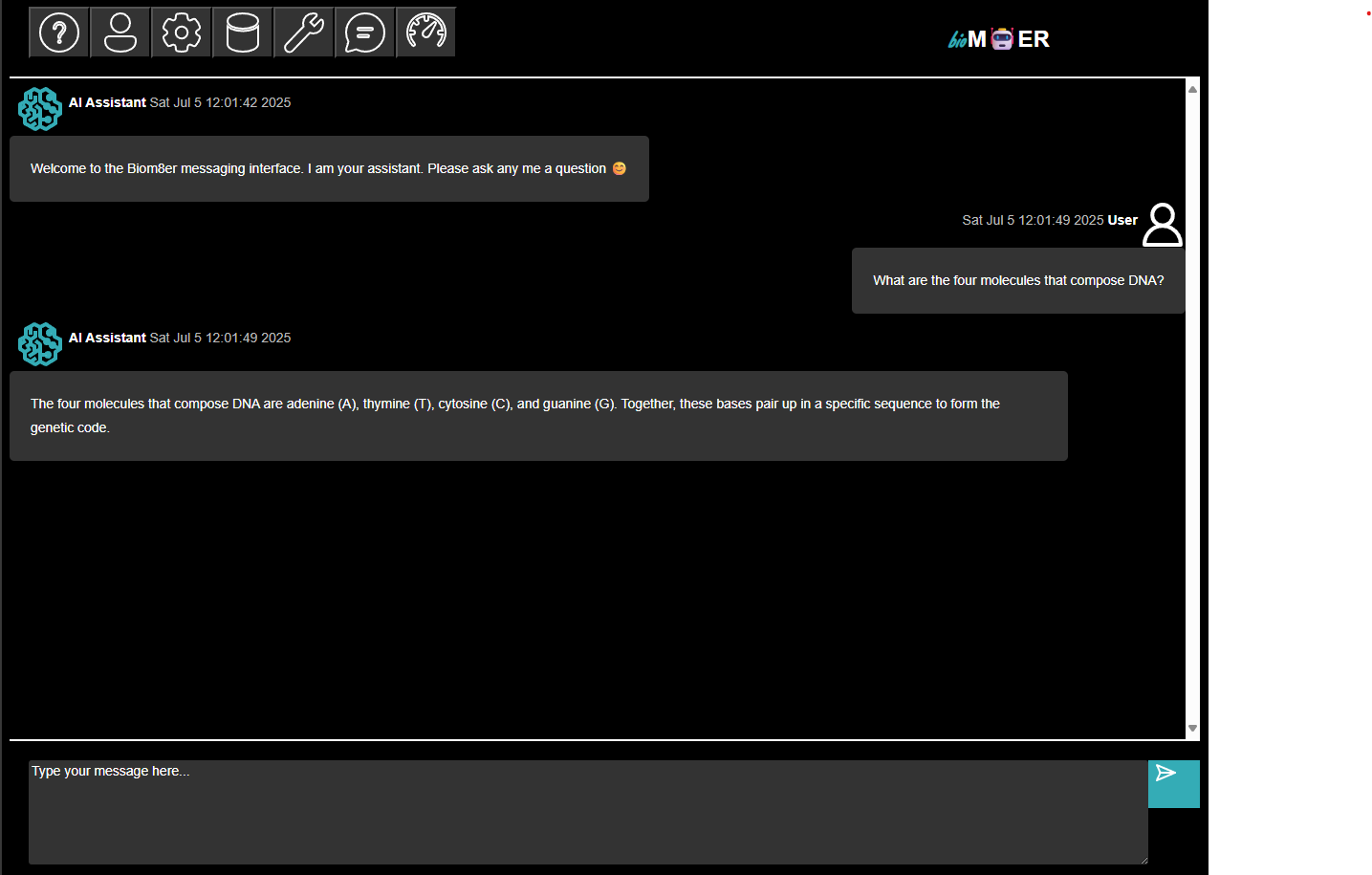
The session ends because there are no further updates to the subjects. If the user publishes a follow-up message, the session will pick-up where it left off with the chat_agent responding to the updated message content.
Next steps
The Chat Agent Session Plan comes with a number of default configurations including the model, number of tokens to sample, temperature of sampling, etc. that can be modified by the user.
Session Plan: Tool Agent
Synopsis
This tutorial describes how the Tool Agent Session Plan uses the phymes-agent and phymes-core crates to build a tool calling agent.
Tutorial
The tool agent adds stochasticity to the agentic AI architecture of the chat agent by conditionally calling an external tool if needed, which can be modeled as a conditional directed cyclic graph.
stateDiagram-v2
direction LR
[*] --> chat_agent: Query
chat_agent --> [*]: Response
chat_agent --> tool_task: Invoke tool
tool_task --> chat_agent: Tool call
The session starts with a query to the chat_agent from the user. Next, the chat_agent may call one or more tools to answer the user query. Next, the tool calls are executed in parallel by the tool_task. Finally, the results of the tool calls are provided to the chat_agent to ground the text generation inference to respond back to the user.
Under the hood, the states of the application are determined by the subjects that are subscribed to and published on by the user, tool_task and chat_agent.
sequenceDiagram
user->>messages: 1
messages-->>chat_agent: 2
tools-->>chat_agent: 3a
config->>chat_agent: 3b
chat_agent->>tool_calls: 4
tool_calls->>tool_task: 5
data->>tool_task: 6
tool_task->>messages: 7
messages-->>chat_agent: 8
tools-->>chat_agent: 9a
config->>chat_agent: 9b
chat_agent->>messages: 10
messages->>user: 11
The sequence of actions are the following:
- The user publishes to messages subject
- The chat_agent subscribes to messages subject when there is a change to the messages subject table.
- The chat_agent subscribes to configs and tools subjects no matter if there is a change or not because the configs provide the parameters for running the chat_agent and the tools describes the schema for the tool calls.
- The chat_agent performs text generation inference based on the messages subject content and tool schemas, and publishes the results to either messages or tool_calls subject.
- The tool_task subscribes to the tool_calls subject when there is a change to the tool_calls subject table
- The tool_task subscribes to the data subject (one or more data tables needed to execute the tool call) no matter if there is a change or not because the data subjects provide the data tables needed for running the tool_task.
- The tool_task retrieves the needed data tables to execute the tool_calls, executes the tool_calls, and publishes the results to the messages subject.
- The chat_agent subscribes to messages subject when there is a change to the messages subject table, which has now been updated with the results of the tool_calls.
- The chat_agent subscribes to configs and tools subjects no matter if there is a change or not because the configs provide the parameters for running the chat_agent and the tools describes the schema for the tool calls.
- The chat_agent performs text generation inference based on the messages subject content, tool schemas, and results of the tool_calls, and publishes the results to either messages or tool_calls subject.
- The user subscribes to messages subject where there is a change to the messages subject table.
The session ends because there are no further updates to the subjects. If the user publishes a follow-up message the session will pick-up where it left off with the chat_agent responding to the updated message and tool_calls content.
Next steps
The Tool Agent Session Plan comes with a number of default configurations including the model, number of tokens to sample, temperature of sampling, etc. that can be modified by the user. A trivial use case is provided for sorting an array in a table that can be used as a starting point for creating more complex realistic use cases involving tools that manipulate (large) tabular data.
Seesion Plan: Retrieval Augmented Generation (RAG) Agent
Synopsis
This tutorial describes how the Document RAG Agent Session Plan uses the phymes-agent and phymes-core crates to build a tool calling agent.
Tutorial
The document RAG agent adds a complex document parsing, embedding, and retrieval Data pipeline to the agentic AI architecture of the chat agent.
stateDiagram-v2
direction LR
[*] --> embed_task: Documents
[*] --> embed_task: Query
[*] --> chat_agent: Query
embed_task --> vs_task: Search docs
vs_task --> chat_agent: Top docs
chat_agent --> [*]: Response
The session starts with an upload of documents to the embed_task to chunk and embed the documents, an upload of the query to the embed_task to embed the query, and a query to the chat_agent from the user. Next, a vector search is performed over the embedded documents to find the top K documents matching the query. Finally, the top K documents are provided to the chat_agent to ground the text generation inference to respond back to the user.
Under the hood, the states of the application are determined by the subjects that are subscribed to and published on by the user, embed_task, vs_task, and chat_agent.
sequenceDiagram
user->>documents: 1
user->>query: 2a
user->>messages: 2b
documents --> embed_doc_task: 3
doc_embed_config --> embed_doc_task: 4
embed_doc_task --> embedded_documents: 5
query --> embed_query_task: 6
query_embed_config --> embed_query_task: 7
embed_query_task --> embedded_queries: 8
embedded_documents --> vs_task: 9a
embedded_queries --> vs_task: 9b
vs_config --> vs_task: 10
vs_task -> top_k_docs: 11
messages-->>chat_agent: 12a
top_k_docs-->>chat_agent: 12b
config->>chat_agent: 13
chat_agent->>messages: 14
messages->>user: 15
The sequence of actions are the following:
- The user publishes to documents subject
- The user publishes to query subject and messages subject
- The embed_doc_task subscribes to the documents subject when there is a change to the documents subject table
- The embed_doc_task subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chunk_processor.
- The embed_doc_task chunks the documents, embeds the chunks, and publishes the results to the embedded_documents subject.
- The embed_query_task subscribes to the documents subject when there is a change to the documents subject table
- The embed_query_task subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chunk_processor.
- The embed_query_task embeds the query and publishes the results to the embedded_queries subject.
- The vs_task subscribes to the embedded_documents and embedded_queries subjects when there is a change to the embedded_documents and embedded_queries subject tables
- The vs_task subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chunk_processor.
- The vs_task computes the relative similarity between the query and document embeddings, sorts the scores in descending order, retrieves the chunk text, formats the results for RAG, and publishes the results to the top_k_docs subject.
- The chat_agent subscribes to messages and top_k_docs subjects when there is a change to the messages and top_k_docs subject tables.
- The chat_agent subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chat_agent.
- The chat_agent performs text generation inference based on the messages subject content and retrieved Top K document chunks, and publishes the results to the messages subject.
- The user subscribes to messages subject where there is a change to the messages subject table.
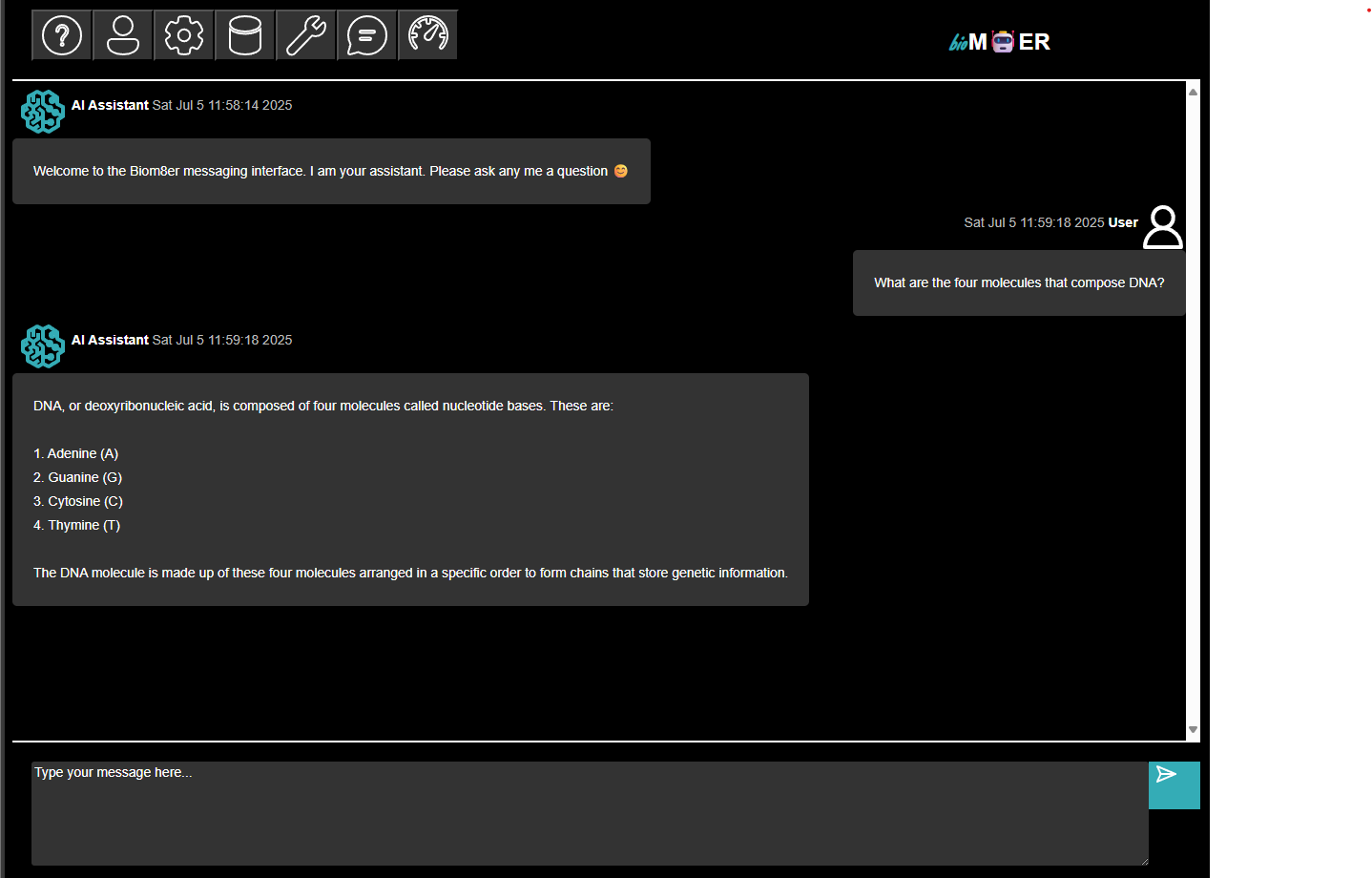
The session ends because there are no further updates to the subjects. If the user publishes a follow-up message or uploads new documents, the session will pick-up where it left off with the chat_agent responding to the updated message and top k document chunk content.
Next steps
The Document RAG Agent Session Plan comes with a number of default configurations including the model, number of tokens to sample, temperature of sampling, etc. that can be modified by the user. For production use cases, we recommend the NVIDIA RAG Blue Print.
PHYMES Server
Synopsis
The PHYMES server crate provides the handlers for querying the SessionContext and publishing on and subscribing to subjects for predefined SessionPlans and serves the web application via the tokio, axum, and tower-http stack.
Tutorial
Security recommendations
phymes-server should be built in --release mode for use in production. When built in debug mode, the CORS security is relaxed to enable interactive debugging of the phymes-app.
Performance recommendations
It is strongly recommend to enable CUDA and CuDNN for NVIDIA GPU acceleration when running token and tensor services locally. If a GPU is not available for running token services, it is strongly recommended to use an API such as OpenAI, NVIDIA NIMs, etc with your API access key passed as an environmental variable instead. Native acceleration for Intel and Apple chipsets are enabled by default when detected. SIMD128 vector instructions for WASM runtimes are enabled by default.
WASM compatibility
Phymes-server can be built for the wasm32-wasip2 and wasm32-unknown-unknown targets (without support for serving HTML and without encryption but with support for APIs). See the developer guide for instructions on running the wasm32-wasip2 CLI application. See an example of how to embed the wasm32-unknown-unknown library in a serverless application.
WASI HTTP can be used in conjunction with wasmtime serve to forward requests to WASM components. However, this has not been implemented yet.
PHYMES App
Synopsis
The PHYMES application crate implements the UI/UX for querying the SessionContext and publishing on and subscribing to subjects for predefined SessionPlans directly or through a chat interface using dioxus. Application builds for Web, Desktop (all OSs), and mobile (all OSs) are theoretically supported, but only Web and Desktop are optimized for currently. The application takes a full-stack approach whereby the frontend is handled by this crate using dioxus and the backend is handled by the phymes-server crate using tokio.
User Interface (UI)
Main menu
Help
Description of menu items
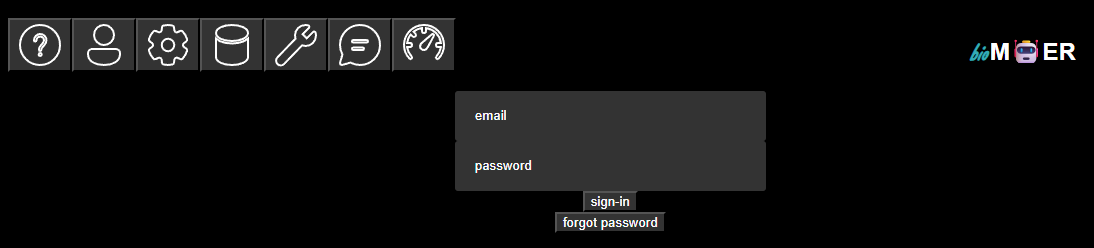
Sign in
User registration and sign in. Each account corresponds to a single email.
Session plans

A list of session plans available to the account. Each session is like a different app with different functionality and state. Only one session can be activated at a time.
Subjects
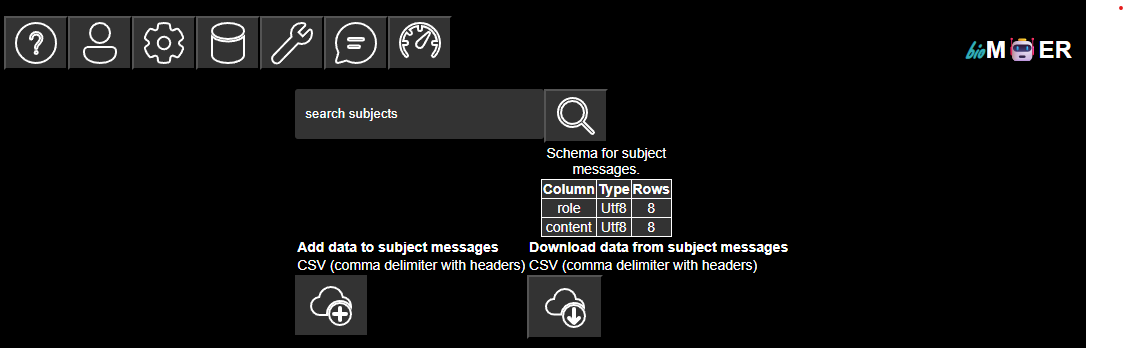
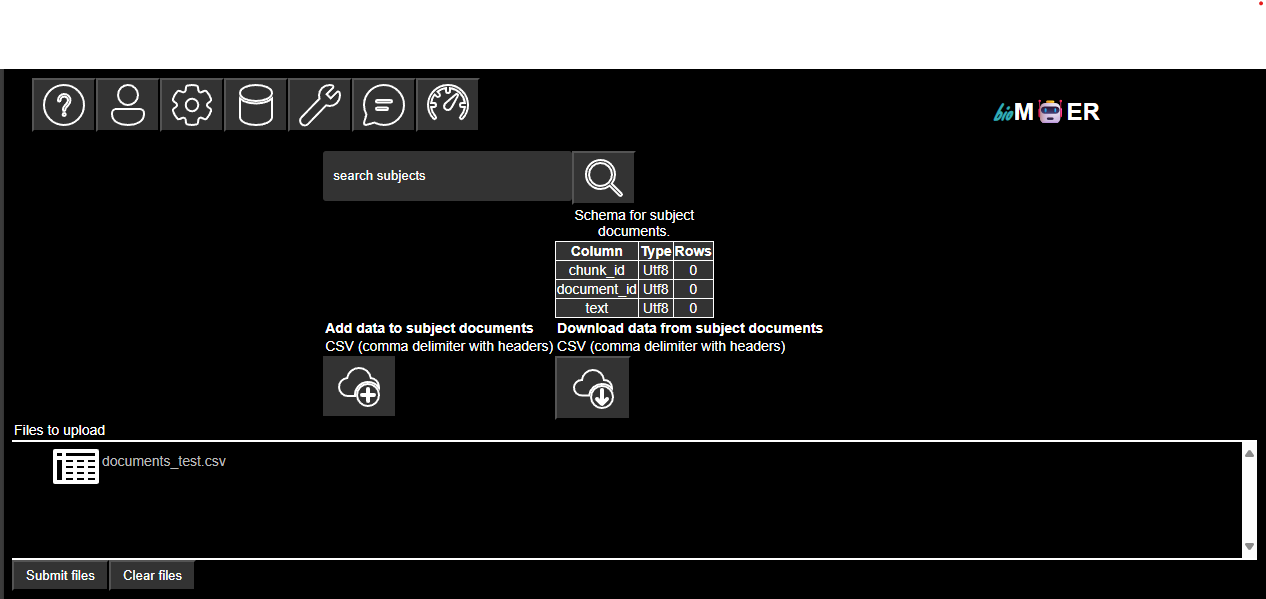
A list of subject associated with the active session plan. A table shows the schema of the subject tables along with the number if rows. The subject tables can be extended or replaced by uploading tables in comma deliminated CSV format with headers that match the subject. The subject tables can also be downloaded in comma deliminated CSV format. Note that all of the parameters for describing how processors process streaming messages are subject tables. Extending the subject tables for a processors parameters will update the processors parameters on the next run. Note that the message history is also a subject table. Extending the messages table is the equivalent of human in the loop.
Tasks
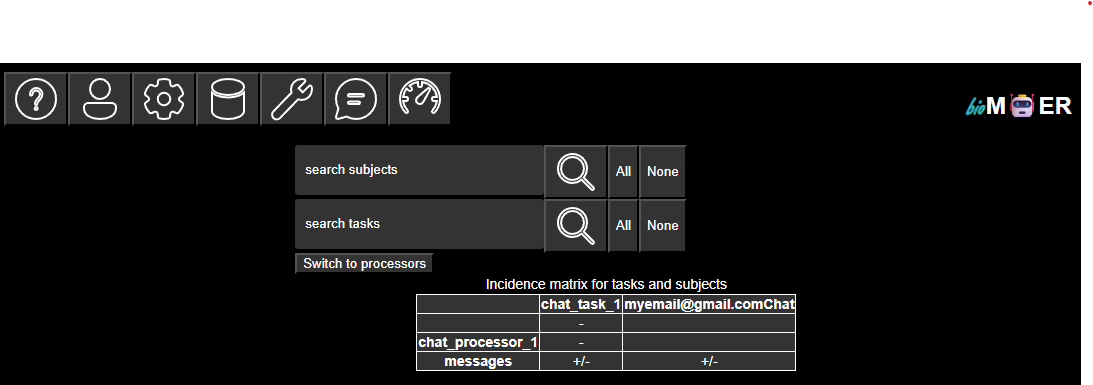
A list of tasks and subjects that the tasks subscribe to and publish on associated with the active session plan. The reaction between tasks and subjects are visualized as an incidence matrix where + indicates publish on and - indicates subscribe to. A toggle button is provided to expand the tasks to their individual processors and collapse the individual processors to their tasks.
Messaging
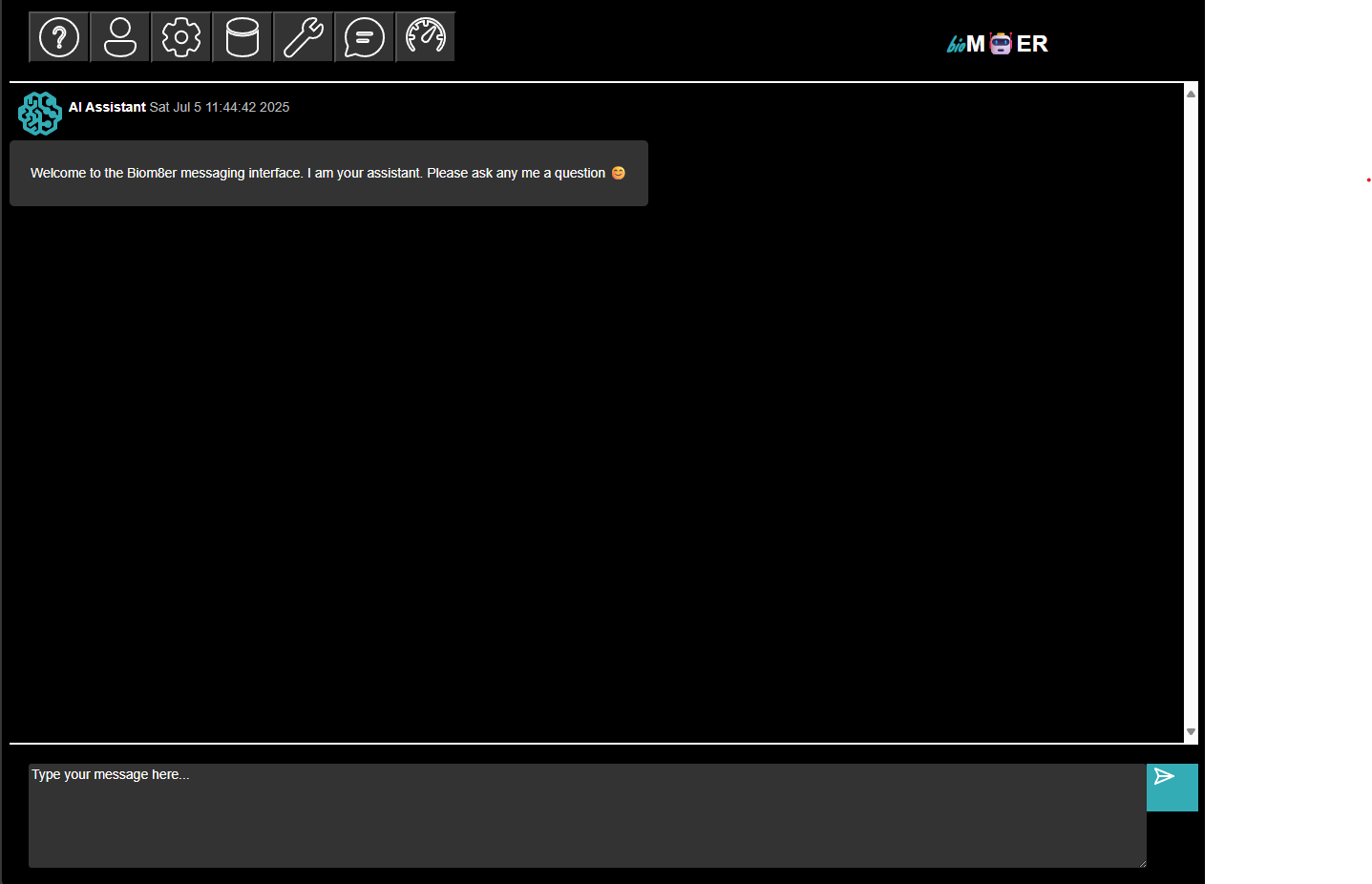
The message history for the active session plan. A chat interface is provided for users to publish messages to the messages subject and to receive subscriptions from the messages subject when the messages subject is updated.
Metrics
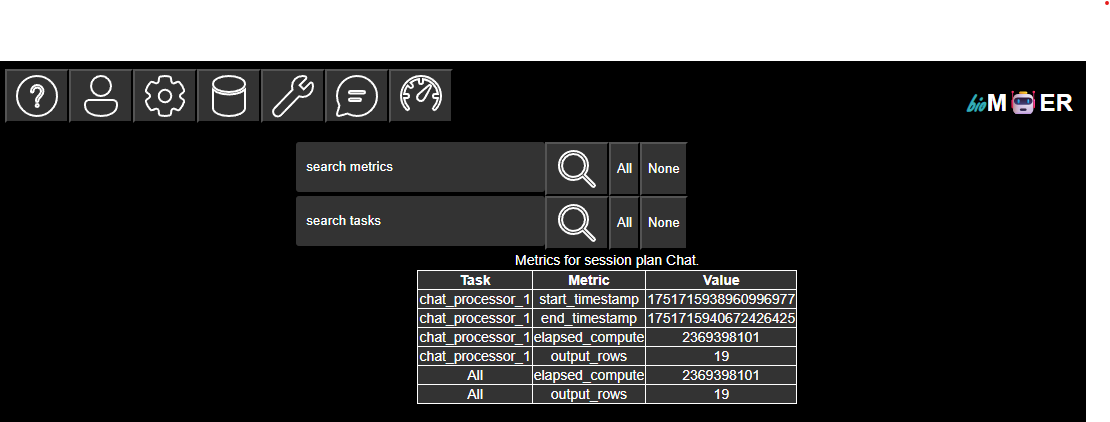
A list of metrics associated with the active session plan. Metrics are tracked per processor. A table in long form displays the values for the tracked metrics. Baseline metrics for row count, and processor start, stop, and total time in nanoseconds are provided. Note each row is approximately one token for text generation inference processors. Please submit a feature request issue if additional metrics are of interest.