Seesion Plan: Retrieval Augmented Generation (RAG) Agent
Synopsis
This tutorial describes how the Document RAG Agent Session Plan uses the phymes-agent and phymes-core crates to build a tool calling agent.
Tutorial
The document RAG agent adds a complex document parsing, embedding, and retrieval Data pipeline to the agentic AI architecture of the chat agent.
stateDiagram-v2
direction LR
[*] --> embed_task: Documents
[*] --> embed_task: Query
[*] --> chat_agent: Query
embed_task --> vs_task: Search docs
vs_task --> chat_agent: Top docs
chat_agent --> [*]: Response
The session starts with an upload of documents to the embed_task to chunk and embed the documents, an upload of the query to the embed_task to embed the query, and a query to the chat_agent from the user. Next, a vector search is performed over the embedded documents to find the top K documents matching the query. Finally, the top K documents are provided to the chat_agent to ground the text generation inference to respond back to the user.
Under the hood, the states of the application are determined by the subjects that are subscribed to and published on by the user, embed_task, vs_task, and chat_agent.
sequenceDiagram
user->>documents: 1
user->>query: 2a
user->>messages: 2b
documents --> embed_doc_task: 3
doc_embed_config --> embed_doc_task: 4
embed_doc_task --> embedded_documents: 5
query --> embed_query_task: 6
query_embed_config --> embed_query_task: 7
embed_query_task --> embedded_queries: 8
embedded_documents --> vs_task: 9a
embedded_queries --> vs_task: 9b
vs_config --> vs_task: 10
vs_task -> top_k_docs: 11
messages-->>chat_agent: 12a
top_k_docs-->>chat_agent: 12b
config->>chat_agent: 13
chat_agent->>messages: 14
messages->>user: 15
The sequence of actions are the following:
- The user publishes to documents subject
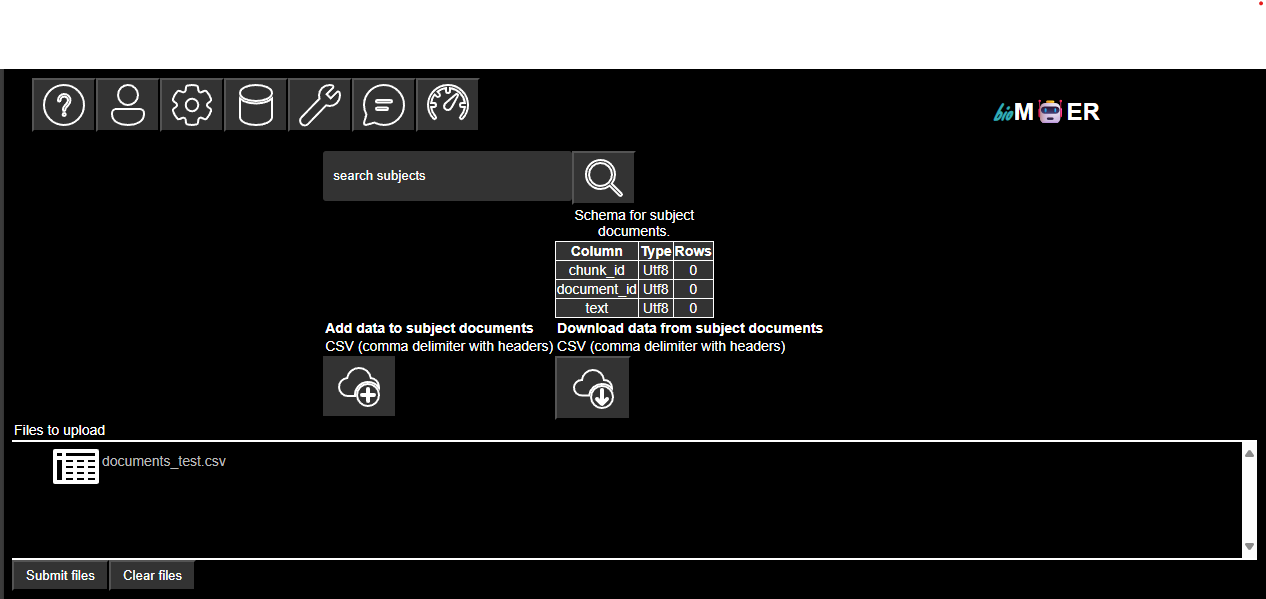
- The user publishes to query subject and messages subject
- The embed_doc_task subscribes to the documents subject when there is a change to the documents subject table
- The embed_doc_task subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chunk_processor.
- The embed_doc_task chunks the documents, embeds the chunks, and publishes the results to the embedded_documents subject.
- The embed_query_task subscribes to the documents subject when there is a change to the documents subject table
- The embed_query_task subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chunk_processor.
- The embed_query_task embeds the query and publishes the results to the embedded_queries subject.
- The vs_task subscribes to the embedded_documents and embedded_queries subjects when there is a change to the embedded_documents and embedded_queries subject tables
- The vs_task subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chunk_processor.
- The vs_task computes the relative similarity between the query and document embeddings, sorts the scores in descending order, retrieves the chunk text, formats the results for RAG, and publishes the results to the top_k_docs subject.
- The chat_agent subscribes to messages and top_k_docs subjects when there is a change to the messages and top_k_docs subject tables.
- The chat_agent subscribes to configs subject no matter if there is a change or not because the configs provide the parameters for running the chat_agent.
- The chat_agent performs text generation inference based on the messages subject content and retrieved Top K document chunks, and publishes the results to the messages subject.
- The user subscribes to messages subject where there is a change to the messages subject table.
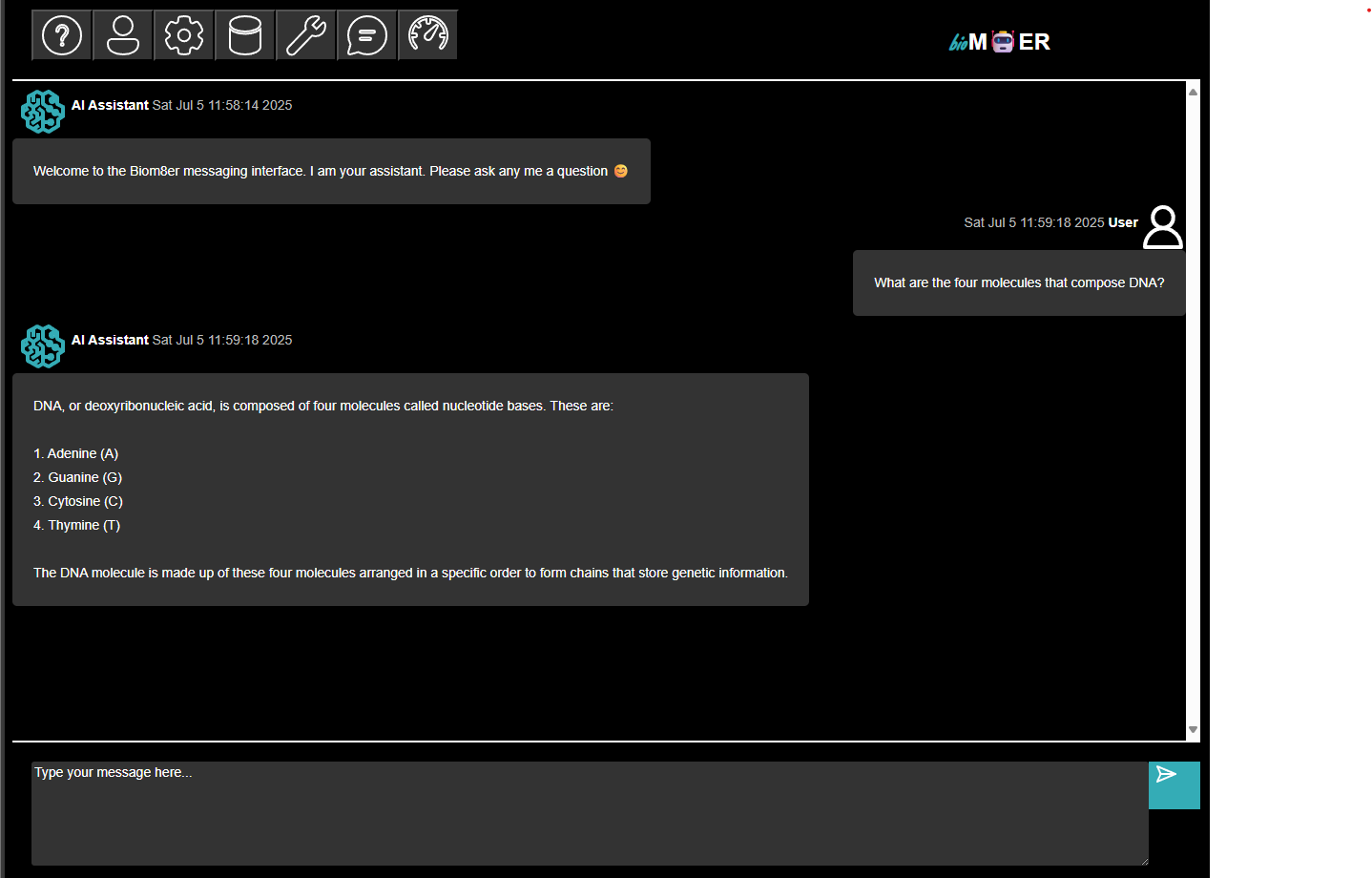
The session ends because there are no further updates to the subjects. If the user publishes a follow-up message or uploads new documents, the session will pick-up where it left off with the chat_agent responding to the updated message and top k document chunk content.
Next steps
The Document RAG Agent Session Plan comes with a number of default configurations including the model, number of tokens to sample, temperature of sampling, etc. that can be modified by the user. For production use cases, we recommend the NVIDIA RAG Blue Print.